Responsabilités de l'administrateur Hadoop
Ce blog sur les responsabilités de l'administrateur Hadoop traite de la portée de l'administration Hadoop. Les emplois d'administrateur Hadoop sont très demandés, alors apprenez Hadoop maintenant!

Ce blog sur les responsabilités de l'administrateur Hadoop traite de la portée de l'administration Hadoop. Les emplois d'administrateur Hadoop sont très demandés, alors apprenez Hadoop maintenant!
Apache Spark s'est révélé être un excellent développement dans le traitement du Big Data.
Apache Hadoop 2.x comprend des améliorations significatives par rapport à Hadoop 1.x. Ce blog parle de Hadoop 2.0 Cluster Architecture Federation et de ses composants.
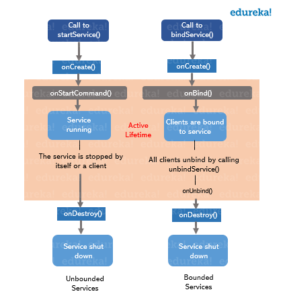
Cela donne un aperçu de l'utilisation de Job Tracker
Apache Pig a plusieurs fonctions prédéfinies. Le message contient des étapes claires pour créer UDF dans Apache Pig. Ici, les codes sont écrits en Java et nécessitent Pig Library
L'architecture HBase Storage comprend de nombreux composants. Examinons les fonctions de ces composants et savons comment les données sont écrites.
Apache Hive est un package d'entreposage de données construit sur Hadoop et utilisé pour l'analyse des données. Hive s'adresse aux utilisateurs à l'aise avec SQL.
La mise en œuvre d'Apache Spark avec Hadoop à grande échelle par les grandes entreprises indique son succès et son potentiel en matière de traitement en temps réel.
NameNode High Availability est l'une des fonctionnalités les plus importantes de Hadoop 2.0 NameNode High Availability avec Quorum Journal Manager est utilisé pour partager les journaux d'édition entre les NameNodes actifs et en veille.
Les responsabilités du poste de développeur Hadoop couvrent de nombreuses tâches.Les responsabilités du poste dépendent de votre domaine / secteur.Ce rôle s'apparente à un développeur de logiciels
Les modèles de données Hive contiennent les composants suivants tels que des bases de données, des tables, des partitions et des compartiments ou des clusters.Hive prend en charge les types primitifs tels que les entiers, les flottants, les doubles et les chaînes.
Ces 4 raisons de passer à Hadoop 2.0 parlent du marché du travail Hadoop et comment il peut vous aider à accélérer votre carrière en vous ouvrant à d'énormes opportunités d'emploi.
Dans ce blog, nous allons exécuter des exemples Hive et Yarn sur Spark. Tout d'abord, créez Hive et Yarn sur Spark, puis vous pouvez exécuter des exemples Hive et Yarn sur Spark.
L'objectif de ce blog est d'apprendre comment transférer des données de bases de données SQL vers HDFS, comment transférer des données de bases de données SQL vers des bases de données NoSQL.
Cloudera Certified Developer for Apache Hadoop (CCDH) est un coup de pouce pour sa carrière. Cet article traite des avantages, des modèles d'examen, du guide d'étude et des références utiles.
Ce blog fournit une vue d'ensemble de l'architecture HDFS High Availability et explique comment installer et configurer un cluster HDFS High Availability en quelques étapes simples.
Apache Kafka continue d'être populaire en matière d'analyse en temps réel. Voici un aperçu du point de vue de la carrière, en discutant des opportunités de carrière et des demandes d'emploi.
Apache Kafka fournit des systèmes de messagerie à haut débit et évolutifs, ce qui le rend populaire dans l'analyse en temps réel. Découvrez comment un didacticiel Apache Kafka peut vous aider
Cet article de blog est une plongée en profondeur dans Pig et ses fonctions. Vous trouverez une démonstration de la façon dont vous pouvez travailler sur Hadoop en utilisant Pig sans dépendance à Java.
Ce blog traite des conditions préalables à l'apprentissage de Hadoop, des éléments essentiels de Java pour Hadoop et des réponses «avez-vous besoin de Java pour apprendre Hadoop» si vous connaissez Pig, Hive, HDFS.