Spark vs Hadoop: quel est le meilleur framework Big Data?
Ce billet de blog parle d'Apache Spark vs Hadoop. Cela vous donnera une idée du bon cadre Big Data à choisir dans différents scénarios.

Ce billet de blog parle d'Apache Spark vs Hadoop. Cela vous donnera une idée du bon cadre Big Data à choisir dans différents scénarios.
Ce blog vous aide à comprendre comment installer et configurer le plugin sbteclipse avec des instructions étape par étape pour exécuter l'application Scala dans Eclipse IDE.
Cet article de blog explique pourquoi vous devez commencer avec Apache Spark après Hadoop et pourquoi apprendre Spark après avoir maîtrisé hadoop peut faire des merveilles pour votre carrière!
Ce didacticiel Apache Drill vous donne toutes les informations dont vous avez besoin pour démarrer avec le moteur de requêtes Apache Drill, l'utilisation avec Hadoop, Big Data et Apache Spark.
Ce blog Spark Hadoop vous dit tout ce que vous devez savoir sur Apache Spark combineByKey. Trouvez le score moyen par élève en utilisant la méthode combineByKey.
Apache Falcon est une nouvelle plateforme de gestion de données pour l'écosystème Hadoop qui simplifie le traitement des flux d'intégration et la gestion des flux sur les clusters hadoop. Apprenez à le configurer.
Ce blog Apache Spark explique en détail les accumulateurs Spark. Apprenez à utiliser les accumulateurs Spark avec des exemples. Les accumulateurs à étincelles sont comme les compteurs Hadoop Mapreduce.
Apprenez tout sur Apache Flink et la configuration d'un cluster Flink dans ce blog. Flink prend en charge le traitement en temps réel et par lots et est une technologie Big Data incontournable pour Big Data Analytics.
Cet article de blog traite de la mise en cache distribuée avec des variables de diffusion et vous permet de commencer à distribuer efficacement de grandes valeurs dans la programmation Spark.
Les certifications CCA et CCP de Cloudera ont remplacé les examens CCDH et CCSHB. Ce blog vous dit tout ce que vous devez savoir sur les nouvelles certifications.
Cet article de blog traite des transformations avec état avec le fenêtrage dans Spark Streaming. Apprenez-en davantage sur le suivi des données entre les lots à l'aide de D-Streams.
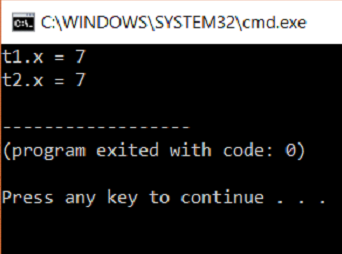
Cet article de blog traite des transformations avec état dans Spark Streaming. Apprenez tout sur le suivi cumulatif et l'amélioration des compétences pour une carrière Hadoop Spark.
Les technologies Hadoop et Big Data révolutionnent l'analyse des soins de santé. Ce blog sur le Big Data dans le secteur de la santé explique comment l'analyse du Big Data peut améliorer les soins médicaux.
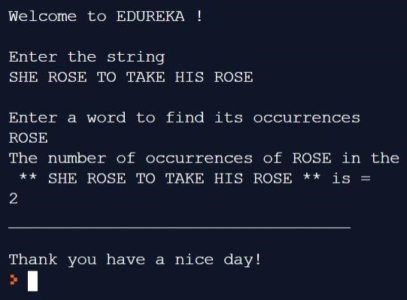
Cet article de blog sur Hadoop Streaming est un guide étape par étape pour apprendre à écrire un programme Hadoop MapReduce en Python pour traiter d'énormes quantités de Big Data.
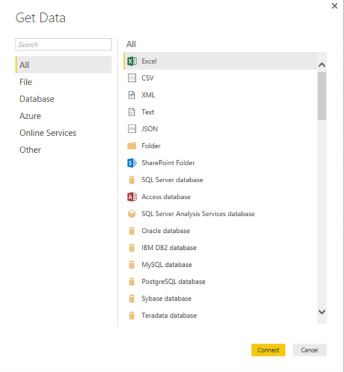
Ce blog sur le tutoriel Big Data vous donne un aperçu complet du Big Data, de ses caractéristiques, de ses applications ainsi que des défis du Big Data.
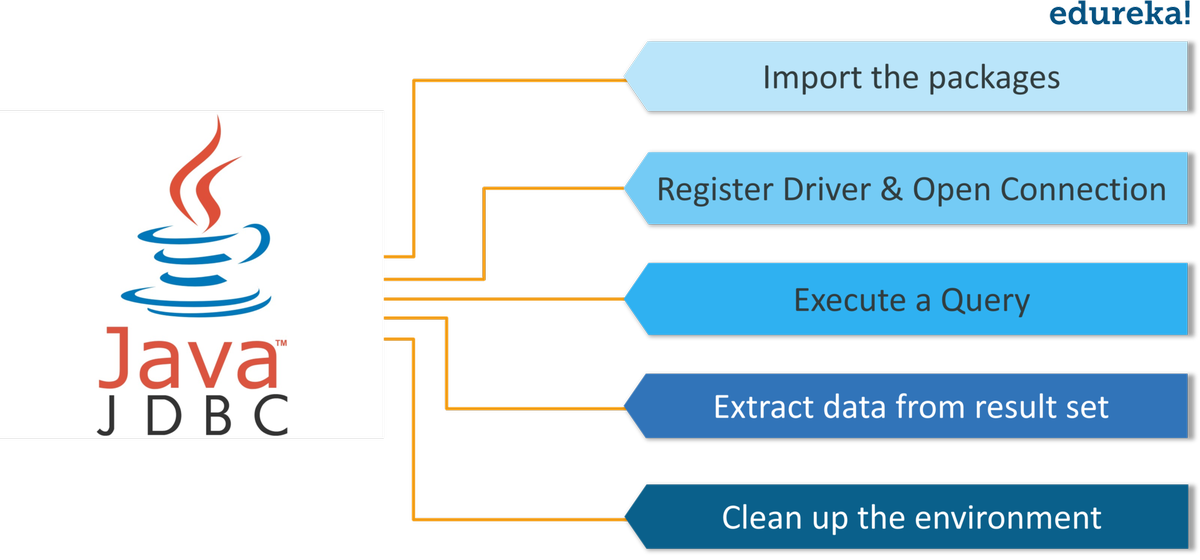
Ce blog du didacticiel HDFS vous aidera à comprendre HDFS ou Hadoop Distributed File System et ses fonctionnalités. Vous explorerez également ses composants de base en bref.
Dans ce didacticiel Splunk, comprenez les différences entre Splunk, ELK et Sumo Logic et déterminez lequel de ces outils vous convient le mieux.
Dans ce blog de cas d'utilisation Splunk, vous comprendrez comment Domino's Pizza a utilisé Splunk pour obtenir des informations sur le comportement des consommateurs et formuler leurs stratégies commerciales.
Ce tutoriel est un guide étape par étape pour installer le cluster Hadoop et le configurer sur un seul nœud. Toutes les étapes d'installation de Hadoop concernent la machine CentOS.
Ce blog parle des différentes commandes HDFS comme fsck, copyFromLocal, expunge, cat etc. qui sont utilisées pour gérer le système de fichiers Hadoop.